Istio Networking Part 1

About the Series
In this two-part series, we embark on a journey into the realm of Istio, a powerful service mesh that has become integral to modern cloud-native applications. In this first installment, our focus will be on understanding the fundamental need for a service mesh, exploring the high-level architecture of Istio, and ending with a brief explanation of Envoy.
In the upcoming part, we will deep dive on a how the Envoy sidecar intercepts all traffic sourced or destined to the application container.
From Monoliths to Microservices
Unless you have been hiding under a rock, you would have heard about the shift from Monoliths to Microservices. Actually, this topic even gets revisited when migrating workloads to the cloud. While working as a Technical Account Manager (TAM) for AWS in the past, we worked with customers to come up with the optimum migration strategy for each workload or component. If this is a topic of interest you can find some details here.
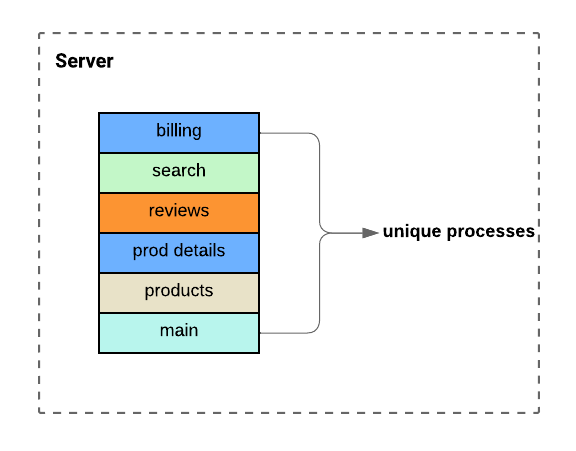
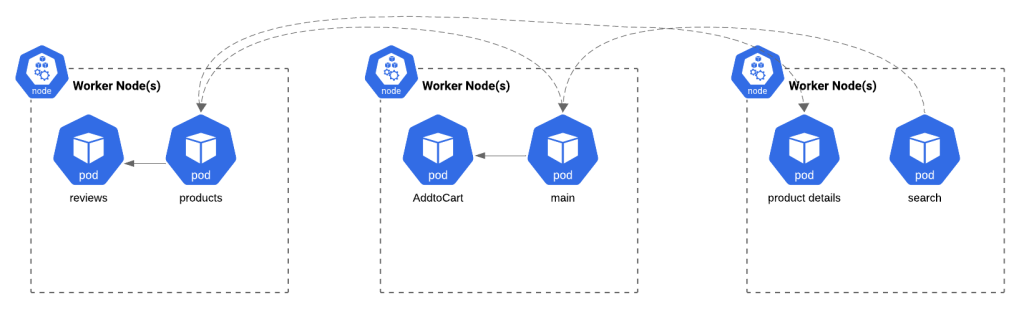
Figure2. Microservices distributed across multiple nodes
Now that we have shifted to running microservices across multiple nodes, a few arising challenges come to the picture:
Network Performance: The performance of the underlying network becomes pivotal in determining the quality of our application’s user experience.
Security: With microservices communicating across networks, encryption becomes paramount to safeguard data in transit.
Observability and Traceability: This is another key concern in microservices where a transaction goes across these different components and we lose the visibility of an end-to-end user journey. The solution to this problem is distributed tracing . In addition, we will always need to have component level metrics & alerts.
Identity & Zero Trust: With the multitude of components and services running in a distributed fashion, we will need to strive to ensure that none of these components gets compromised and even if any of those components were to get compromised, we need to ensure that it cannot be used as a pivot to attack other critical services. This requires a solid identity foundation whereby each service has an identity and a role. Thus, any service to service call has to be authenticated & authorized with least privilege principle in mind. Advanced Load Balancing: Each of the components depicted as part of an application will have a number of replicas for purposes of scaling and high availability, thus at a minimum we will need to distribute load across all endpoints of a particular service in an efficient manner. This encompasses requests from external users or customers as well as requests between those microservices. Microservices allows pushing newer versions of individual components (billing, product details, ..etc) more frequently. This is another critical use-case for load balancing where for instance you can have 95% of requests target the stable version and only 5% target the updates versions and keep adjusting the weights based on your testing. Another possibility is sending your internal authenticated users to the new version and keeping external customers on the production/stable version.
Resiliency: As per the Principles of Chaos Engineering website, “Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.” Distributed complex systems are always prone to fail however our objective should be to stop the overall failure of the application or service we provide customers and end-users. Thus, we need tooling that will help application owners test their application in chaotic conditions whereby for instance a component responds with errors or delay a response and see the effect on the end-to-end user journey.
Manageability: Just like Kubernetes offers a single API to manage all resources, it is a must that all those capabilities (1-6) be centrally orchestrated.
These challenges birthed the need for a service mesh, with Istio emerging as the de facto solution. It might be interesting to note that prior to service mesh, attempts were made to solve those challenges with software libraries like Stubby and Hystrix.
Istio Architecture
At a high level Istio’s architecture has 2 main components:
Envoy proxies (dataplane): This is the data plane component of the solution. The Envoy proxy runs as a sidecar i.e. it runs alongside the main service in the pod to provide additional functionality which in our case is security, observability, resiliency and load balancing.
Istio Control Plane (istiod): So we have added those Envoy proxies, but we still need a central management & operations to manage all of those proxies at scale. Istiod or the Istio Control Plane actually fills this gap whereby it manages all of the configurations of the Envoy proxies. One of the reasons that Envoy was chosen as the sidecar for Istio deployment is its inherent ability to be dynamically configured via APIs. As a side note, when running Istio with Kubernetes, Istio automatically detects the services and their endpoints in that particular cluster and makes an entry for each service within its internal registry.
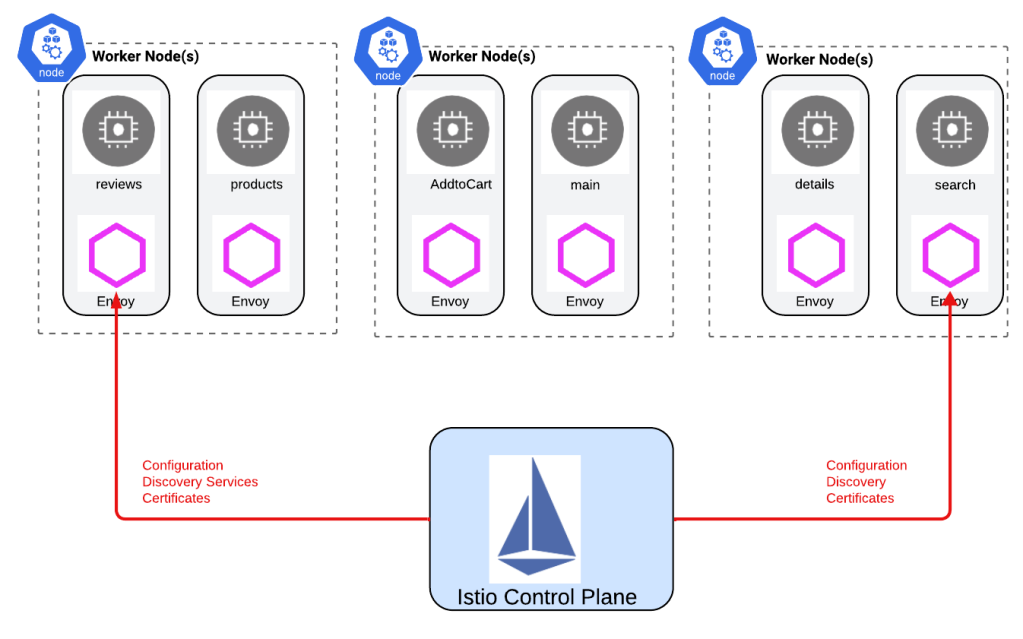
Figure3. Istio Architecture

Figure4. Istio Data Plane
It is also worth noting that there is another mode of Istio named Ambient Mesh that removes the need of sidecars from the dataplane. More on this can be found here.

Quick Word on Envoy
I will end up this part by a very high level overview of how Envoy works. If you have done any work on Load Balancers, Envoy is pretty similar from a grand scheme of things.
Client or the requester is referred to as downstream.
The Server is referred to as upstream.
Envoy just like any other Load Balancer, needs to have a listener whereby Envoy is waiting for requests that match a particular address or any address and a particular port. An example could be 0.0.0.0:80 whereby the listener will accept requests on any interface with a destination port of 80. Any request that doesn’t hit the listener port is ignored by Envoy.
Once Envoy receives the packet on the listener, it subjects it to a Filter Chain i.e. a set of filters which determine how to deal with the incoming packet. You might want an L3/L4 Load Balancer and thus might use the TCP proxy filter or need forwarding based on L7 HTTP semantics with HTTP Connection Manager. TLS inspector is another commonly used filter to detect if the transport is plaintext or TLS and if TLS can detect Server Name Indication (SNI) and/or Application Layer Protocol Negotiation (ALPN). This filter chain, assuming the request is accepted, will most likely finalize by sending the request to the Clusters (Upstream components).
Clusters can be envisioned as collections of endpoints or targets. In a highly available application, a Cluster could comprise multiple Nginx web servers. Once a specific cluster is chosen, the remaining decision lies in selecting an endpoint within the cluster, typically governed by a load balancing policy.
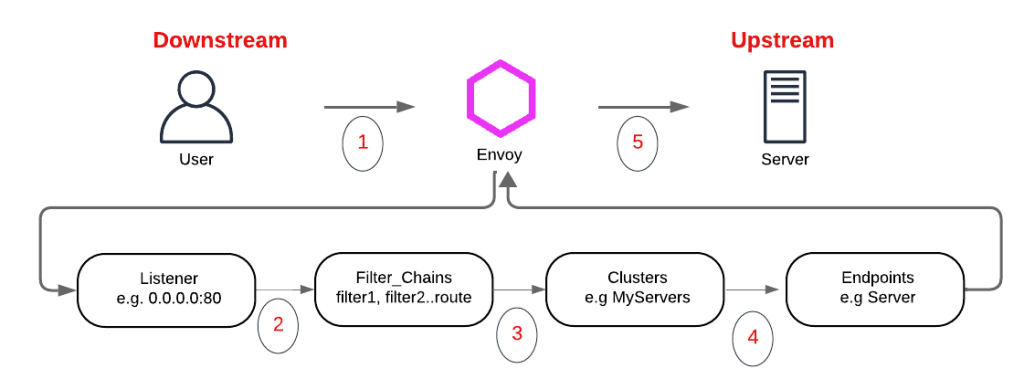
Figure5. Envoy Constructs: Listeners, Filters, Clusters & Endpoints
In the upcoming part, we’ll embark on a deep dive into the intricate workings of how Envoys proxy intercepts all traffic sourced and destined for the container.




